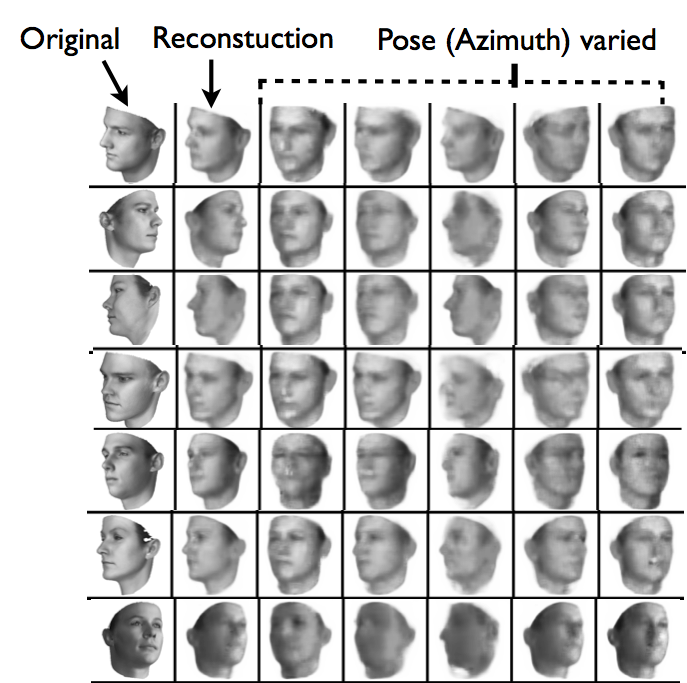

Demo of our model re-rendering a given static image with different 3D sweeps on (a) elevation and (b) azimuth and (c) light neurons.
(a)
(b)
(c)
Deep Convolutional Inverse Graphics Network
This paper presents the Deep Convolution Inverse Graphics Network (DC-IGN) that aims to learn an interpretable representation of images that is disentangled with respect to various transformations such as object out-of-plane rotations, lighting variations, and texture. The DC-IGN model is composed of multiple layers of convolution and de-convolution operators and is trained using the Stochastic Gradient Variational Bayes (SGVB) algorithm (Kingma and Welling). We propose training procedures to encourage neurons in the graphics code layer to have semantic meaning and force each group to distinctly represent a specific transformation (pose,light,texture,shape etc.). Given a static face image, our model can re-generate the input image with different pose, lighting or even texture and shape variations from the base face. We present qualitative and quantitative results of the model's efficacy to learn a 3D rendering engine. Moreover, we also utilize the learnt representation for two important visual recognition tasks: (1) an invariant face recognition task and (2) using the representation as a summary statistic for generative modeling.
Contributors: Tejas D. Kulkarni* (MIT), Will Whitney* (MIT), Pushmeet Kohli (MSR Cambridge, UK), Joshua B. Tenenbaum (MIT)
Note: First two authors contributed equally and are listed in an alphabetical order.
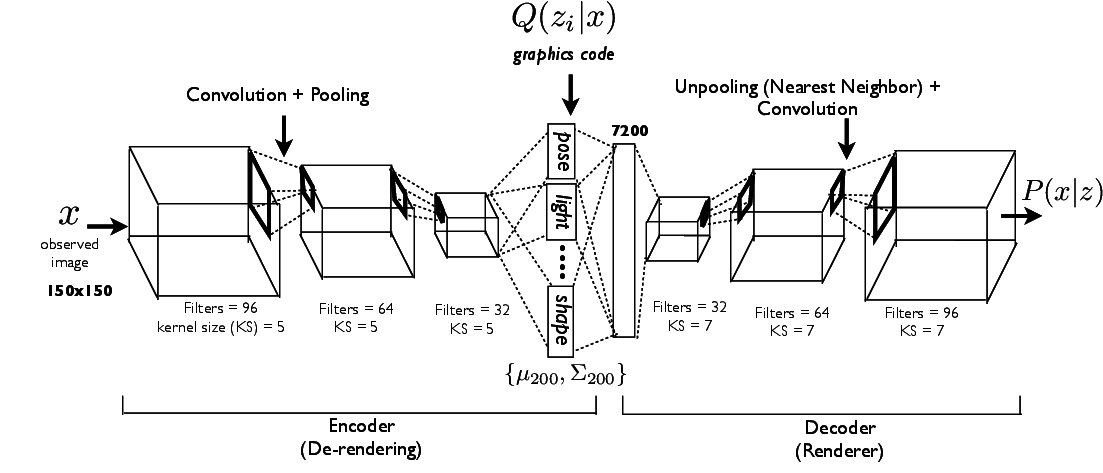
Model Architecture
Deep Convolutional Inverse Graphics Network (DC-IGN) has an encoder and a decoder. We follow the variational autoencoder (Kingma and Welling) architecture with several variations. The encoder consists of several layers of convolutions followed by max-pooling and the decoder has several layers of unpooling (upsampling using nearest neighbors) followed by convolution. (a) During training, data (x) is passed through the encoder to produce the posterior approximation Q(z_i|x), where z_i consists of scene latent variables such as pose, light, texture or shape. In order to learn parameters in DC-IGN, gradients are backpropagated using stochastic gradient descent using the following variational object function: -log(P(x|z_i)) + KL(Q(z_i|x)||P(z_i)) for every z_i. We can force DC-IGN to learn a disentangled representation by showing mini-batches with a set of inactive and active transformations (eg face rotating, light sweeping in some direction etc). (b) During test, data x can be passed through the encoder to get latents z_i. Images can be re-rendered to different viewpoints, lighting conditions, shape variations etc by just manipulating the appropriate graphics code group (z_i), which is how one would manipulate an off the shelf 3D graphics engine.