Abstract
We introduce a neural network architecture and a learning algorithm to produce factorized symbolic representations. We propose to learn these concepts by observing consecutive frames, letting all the components of the hidden representation except a small discrete set (gating units) be predicted from the previous frame, and let the factors of variation in the next frame be represented entirely by these discrete gated units. The model thus learns binary-valued gatings which correspond to symbolic representations. We demonstrate the efficacy of our approach on datasets of faces undergoing 3D transformations and Atari 2600 games.
You can read the full paper on Arxiv.
Results
These animations are generated by encoding one input image, then varying the value of a single component of this encoded representation before rendering the representation with the decoder. Each animation thus demonstrates the meaning of a single hidden unit of the autoencoder.
Our first dataset is frames from Atari 2600 games. Just by watching video of gameplay, our model learns cleanly disentangled representations of the position of the paddle and the number of lives remaining in Breakout. In Space Invaders, it learns to represent the state of the aliens with a single unit, including the animations they make as they move across the screen. Though the renderings here are from one input frame each, these transformations work equally well with any game state; the model learns to symbolically represent these latent factors of variation from raw pixels.
 Moving the paddle.
Moving the paddle.
 Counting remaining lives.
Counting remaining lives.
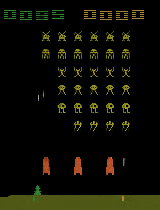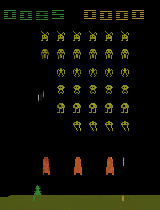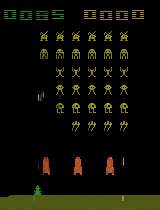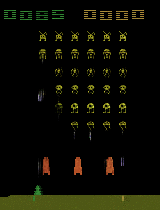 Animating the aliens.
Animating the aliens.
This dataset consists of rendered images of faces as they move up and down or left and right, and as the light source moves around them. The model is able to learn to infer the pose and lighting of these faces completely unsupervised; additionally, it can re-render the input face with a different pose or lighting. This result is comparable to the DC-IGN, but needs no supervision.



Code
All the code for this project is available at https://github.com/willwhitney/understanding-visual-concepts. It's very much under active development, so use it at your own risk.
Citation
If this paper was helpful, or you use our code, please cite us!
@article{whitney2016understanding,
title={Understanding Visual Concepts with Continuation Learning},
author={Whitney, William F. and Chang, Michael and Kulkarni, Tejas and Tenenbaum, Joshua B.},
journal={arXiv preprint arXiv:1502.04623},
year={2016}
}